Teaching and Refining NLP Models with Human Explanations
by Qinyuan Ye, March 13, 2021 (Updated on Oct 20, 2021)
Introduction
Neural models achieve strong performance in a wide range of NLP tasks, such as text classification, reading comprehension, summarization, etc., at the cost of large-scale, human-annotated data. The curation of these datasets are prohibitively expensive, typically requiring hundreds of hours and thousands of dollars. Moreover, modern NLP models are mostly “black-box”, in that the parameters of a model and the computations producing the final predictions are not directly interpretable to human, making these powerful models less transparent and trustworthy.
But how to train a competent model with fewer human efforts? How do we ensure a model has learned skills, instead of shortcuts such as dataset biases? Using large pre-trained language models with strong prior knowledge obtained during self-supervised learning (e.g., BERT, RoBERTa, T5), plus robust and efficient fine-tuning techniques (e.g., SMART, iPET, LM-BFF) partially solve the problem, as these models exhibit strong capability even in low-resource scenarios. Building upon this, can we further improve, by changing the way we supervise the model? For example, within limited time, how can we communicate our needs to a neural network more efficiently and transparently? These needs may include teaching a specific skill, or refining a learned model by patching its mistakes.
In this blog post, we discuss how to address these problems by enabling machines to “learn from human explanations”. We first review existing efforts that leverage human explanations, and then introduce our continued efforts in using compositional explanations as an novel way of supervision to train models more efficiently and transparently.
Learning from Expalantions
Motivation
Humans learns efficiently. We are able summarize the ‘‘gists’’ from very few demonstrations. Then we apply such knowledge when we encounter new, unseen cases.
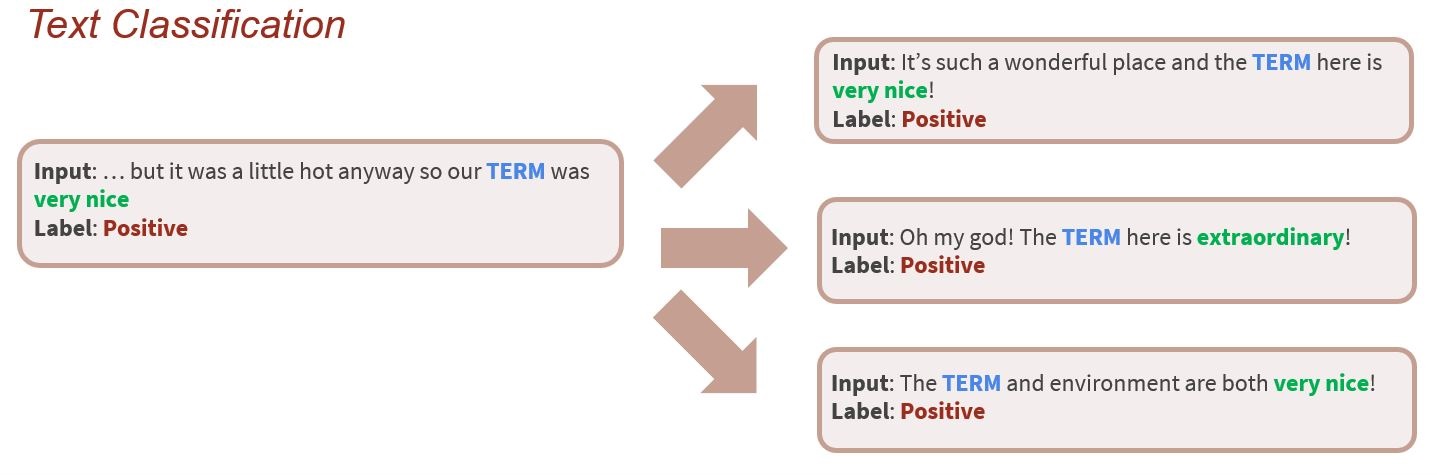
Figure 1. Humans generalize from very few demonstrations.
However this is not the case with traditional supervised learning paradigm. In this paradigm, models learn from individual examples, e.g., sentence-label pairs. Labels (usually represented by indices), only tell the final answers; they do not tell the reason why, or the “gist” that can be deduced from examples.
To enable machines to learn like humans, we advocate for a novel learning paradigm, learning from human explanations, where the training example (e.g., sentence-label pair) is typically augmented with an explanation. We hope that explanations describing why the label is correct and how to solve similar problems can lead to more efficient learning.
Related Work
It is hard to compile a formal definition for explanation, so here we roughly define explanations as additional information that justifies labels or model predictions. Explanations can take various forms, including but not limited to (1) rationale; (2) post-hoc explanation; and (3) natural language explanations.

Figure 2. Different formats of explanations.
Rationales are highlighted substrings in the input text that significantly influenced annotator judgement. It was used in Zaidan et al., 2007 for sentiment classification, and was later extended to complex question answering tasks (Yang et al., 2018, Dua et al., 2020). The question in Fig. 2 (Left) (from Dua et al., 2020) asks how many touchdown passes (an important play in football) did someone throw. The answer is three and the rationale contains the three touchdown events separately.
Post-hoc explanations, on the other hand, aims to help people interpret model behavior after it is trained. This is typically done by assigning importance scores to tokens and phrases in the input. One straightforward way to evaluate the importance of one token in the sentence is by occluding it in the input and see how this influence the prediction. For example, to label “The movie is fantastic” as positive sentiment, “fantasitic” plays an important role, since we cannot infer anything from “The movie is <padding>”; “movie” plays a less important role, since “The <padding> is fantastic” still sounds positive. To improve the interpretability and faithfulness, Ribeiro et al. (2016) introduced LIME and Jin et al. (2020) proposed hierarchical explanations (see Fig. 2 (Middle)).
Natural language explanation are open-ended sentences that explain a human annotation decision or a model prediction. They are less restricted in format compared to rationale and post-hoc explanations mentioned earlier, giving more flexibility to human annotators. Camburu et al. (2018) introduced e-SNLI dataset, which contains both rationales and a natural language explanation for one NLI example. CoS-E dataset (Rajani et al., 2019) extends from CommonsenseQA dataset (Talmor et al., 2018) and additionally collects explanations. For example, “People who are drunk have difficulty speaking” explains the question in Fig. 2 (Right).
Methods to leverage these additional information in explanations also differ. Take natural language explanations as an example, methods to incorporate them during model learning include using them for representation engineering, as auxiliary task, or for genrating noisily labeled data.
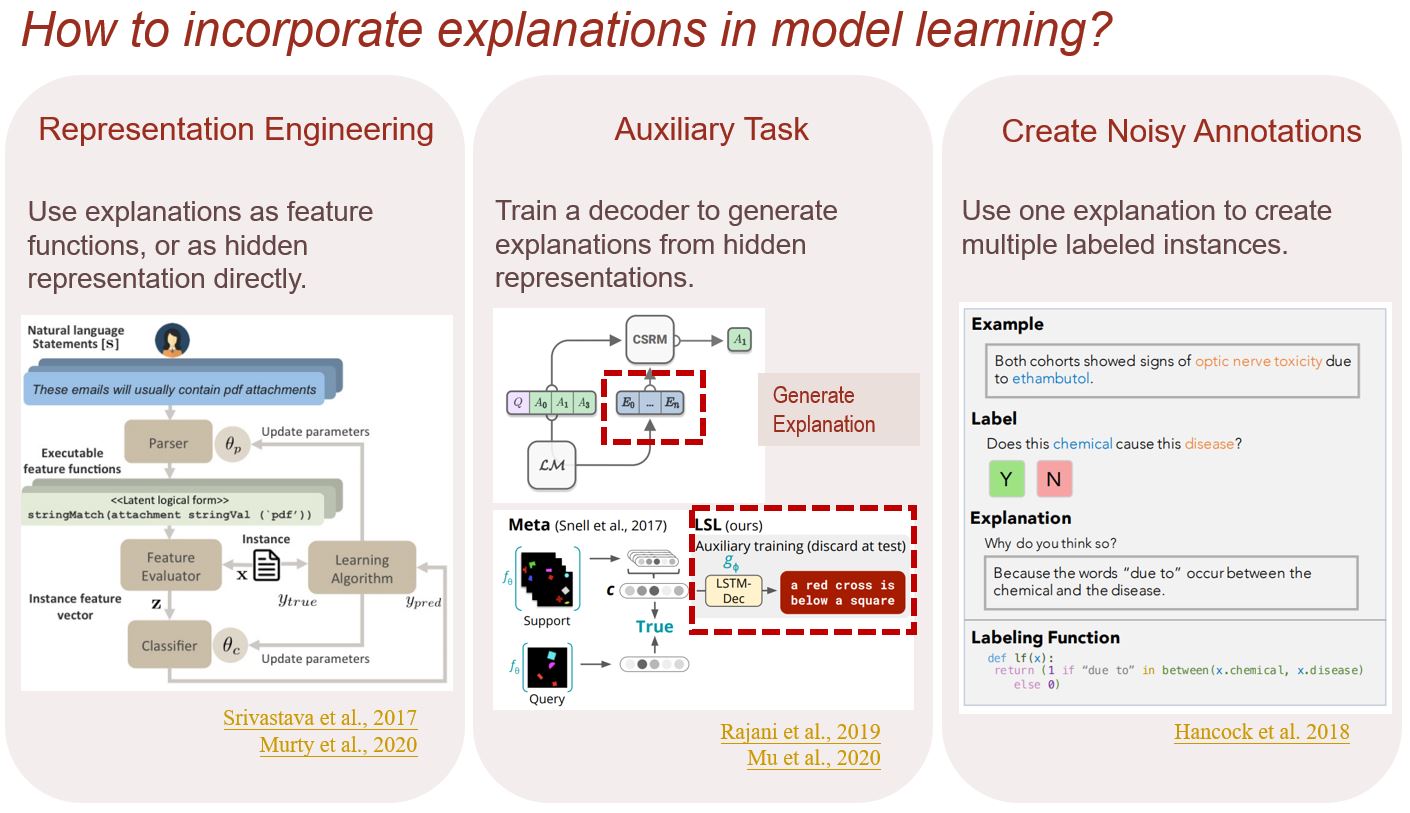
Figure 3. Different ways to incorporate explanations in model learning.
To use explanations as part of representation, Srivastava et al. (2017) proposed joint concept learning and semantic parsing, where the semantic parser transforms explanations (e.g., “These emails will usually contain pdf attachments.”) into feature functions (e.g., a function that checks whether an email has attachment, and outputs True or False). The features produced by the functions are used to train a classifier for concept learning (e.g., determining “negative reviews” or “spam emails”). Murty et al. (2020) leverages an natural language inference (NLI) model as feature functions. The explanation is used as hypothesis and the input sentence is used as premise in the NLI model. This methods avoids building a domain specific lexicon for semantic parsing, and exhibit strong performance in low-resource regimes.
Alternatively, researchers have explored using explanation generation as an auxiliary task. CAGE framework (Rajani et al., 2019) first fine-tune a GPT model (Radford et al. 2018) to finish the sentence “<question>, <choice1>, <choice2>, or <choice3>? commonsense says …”. Then the generated explanation and the choices are fed into a downstream commonsense reasoning model to make the final prediction. Mu et al. (2020) regularizes visual representation by decoding natural language description of a class from the representation.
Explanations can be also used to create noisily labeled data. BabbleLabble, proposed by Hancock et al. (2018), is a framework that trains a relation classifier from scratch with only explanations as supervision. Similar to Srivastava et al. (2017), the explanations are first parsed into executable functions; however, in BabbleLabble they are labeling functions instead of feature functions. The authors attribute this to “utilizing a larger feature set and unlabeled data”.
Continuing on the line of work in BabbleLabble (creating noisily labeled data), our recent work studies how to teach skills such as text classification and reading comprehension to NLP models by collecting explanations, and how to overcome challenges when expalanations are unstructured, compositional, and limited in its coverage to unlabeled data. In addition, we explores whether we can hot-fix a model’s spurious behavior by providing compositional explanations.
As a side note, two very recent work provide systematic reviews of learning from explanations and cover more details. Wiegreffe et al. (2021) focuses more on current resources and datasets of explanations, and Hase et al. (2021) focuses more on existing methods to leverage explanations in model learning and proposes an analysis protocol.
Teaching Skills
Our works, Learning from Explanations with Neural Execution Tree (NExT) and Teaching Machine Comprehension with Compositional Explanations (NMTeacher), explore how to teach text classification and machine reading comprehension to neural models with compositional explanations. Prior work uses the explanation to annotate data rigidly, paying less attention to linguistic variations of input text, and compositionality of explanations. Our works try to address these limitations by teaching machines to generalize from what are described in the explanations.
As a brief recap, BabbleLabble (Hancock et al., 2018) has explored training classifiers from explanations, with two major steps.
- Step 1: Explanation -> Rules (or “labeling functions”)
- Step 2: Rules + Unlabeled Data -> Lots of Noisily Labeled Data

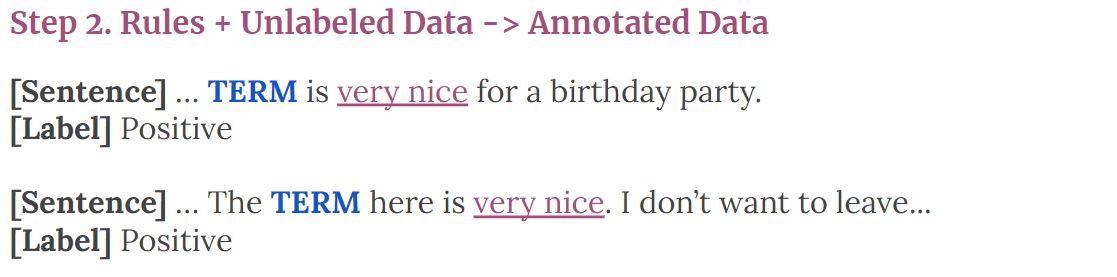
Figure 4. Step 1 and 2 for training classifiers from explanations.
Human learns even more efficiently than this. We are aware of common linguistic variants; thus we generalize from ‘‘very nice’’ to ‘‘super nice’’ and ‘‘extraordinary’’ based on our prior knowledge. Also, we consider five words away from the TERM to be a useful signal, though it breaks the contraint of being two words away. Given these intuitions we introduce step 3 in NExT:
- Step 3: Softened Rules + Unlabeled Data -> Even More Noisily Labeled Data
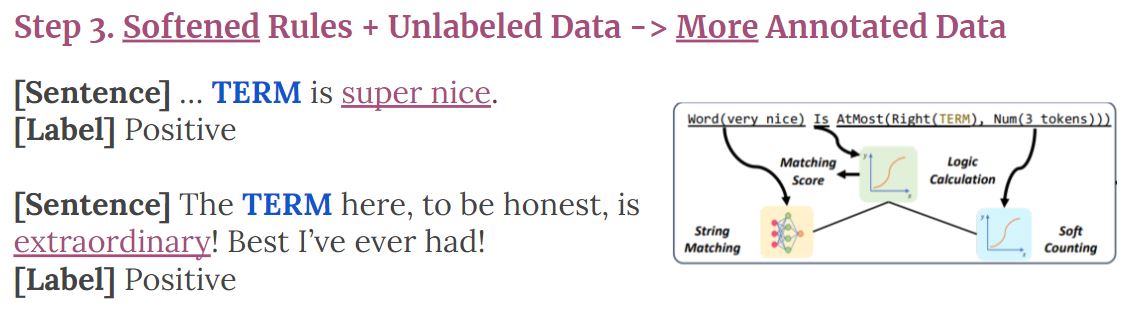
Figure 5. Step 3, softened matching, proposed in our NExT framework.
But how to execute rules softly? In NExT, we proposes to improve this generalization ability by (1) modularizing the function execution, and (2) implement each module with a small neural network (see Fig. 5 (Right)). The underlying execution of the function is re-formulated with a tree structure, which we named as Neural Execution Tree (NExT). In the tree, each node represents a small execution unit in the function. For example, we use FIND module to find semantically similar phrases (i.e., generalize from “very nice” to “super nice”). The string matching module is a bi-directional LSTM model that outputs a score for each position of the input sentence that represent how likely “very nice” or its synonym appears here. In addition to string matching, we softened the rule matching with a soft distance counting (i.e., what if the distance is 5 when the constraint is 3?) and soft logic (i.e., what if two constraints are connected by “and”, but both constraints are only partially satisfied?).
In NMTeacher we further explore the possibility of teaching a more complex skill, machine reading comprehension (MRC), with human explanations. MRC requires a model to extract a span from the context paragraph as the answer to a question. Compared to classification problems, MRC is more challenging since it does not have a pre-defined set of labels to choose from and does not have ‘‘anchor words’’ such as the TERM in sentiment analysis. Moreover, MRC introduces more variations in the problem solving ability – it’s harder to describe the thought process with explanations, and one explanation has even sparser coverage.
We address these problems by (1) introducing the concept of variables (e.g., X, Y, Z, ANS) and (2) designing a search process to fill variables with appropriate values (e.g., assign Switerland to X). Variables such as X and Y enable high-level abstraction. For example, The question “How long has Switzerland been neutral?” would be abstracted into “How long has X been Y” where X and Y should be a noun and an adjective respectively. The sentence containing the sentence will probably follow the pattern “X has been Y [ANS: (since …)]”.

Figure 6. Examples of explanations for reading comprehension in NMTeacher.
When attempting to apply the explanation to more unseen examples, we use a search algorithm that finds potential candidates for variables. For example, in the new question “How long has Youtube website been up?” contains multiple noun phrases, so X can be either "Youtube", "website" or "Youtube website". Our search algorithm is responsible for determining X="Youtube" and Y="up" in so many combinations. In this way we are able to identify the answer ANS="since May 2015" from the sentence “Youtube has been up since May 2015”. Similarly, we identify answer spans for more unlabeled instances and formulate a training set.
In addition, softened matching techniques in NExT are also applicable here (e.g., what if in the question Y="launched" but in the context Y="up".). For more details, please check our NMTeacher Homepage.
Refining A Trained Model
We can do more than teaching skills using explanations. Consider a scenario where you downloaded a trained model for your purpose, but the performance is not as desired since you identified some buggy predictions from this model. In our recent work, Refining Neural Networks with Post-hoc Explanations (REMOTE), we try to communicate our suggestions to refine a trained model with human explanations.
Towards this goal, we first need to identify where a model goes wrong – a model interpretation algorithm that tells us how a model arrives at its current predictions. We use hierachical post-hoc explanation algorithm (Jin et al., 2020), which computes importance scores for tokens and spans in the sentence (Fig. 7), representing their importance towards making a final prediction.
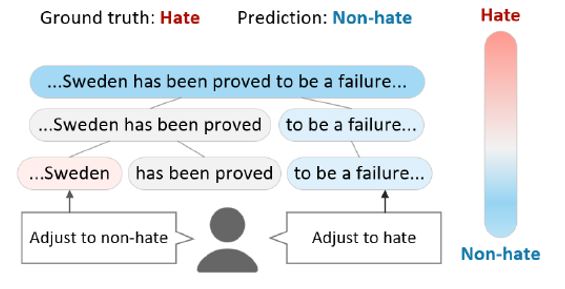
Figure 7. Model refinement with explanations.
Next, we apply this post-hoc algorithm to the instances for which we believe the current model produces wrong predictions. In Fig. 7, we use a hate-speech classification example, “Sweden has been proved to be a failure”. The current model predicts “Non-hate” but the correct prediction is “Hate”. With the post-hoc explanations, we see why the model got wrong with this input. We then provide our suggestion to refine the model, e.g., focus more on the word “failure”, but pay less attention to the word “Sweden”, when identifying Hate instances.
These suggestions are used to regularize the model, by updating the model paramters to align human-preceived importance and the scores produced by post-hoc explanation algorithms. In addition, these suggestions are generalizable across datapoints when softened matching technique is applied.
Our empirical results on two text classification tasks demonstrate the effectiveness of our proposed method. Moreover, we observe improved model fairness after refining a hate-speech detection model. The refined models are less biased towards group identifiers (e.g., Asians). With REMOTE, we can play our parts in responsible and trustworthy AI, by maintaining and refining the model over time, fixing its mistakes, and reducing the unintended harm produced by the model, if there is any.
Looking Forward
Human intelligence is powerful. We learn by looking at our past and capture the essence from it. We reflect on ourselves, learn from our own mistakes, and try to avoid them in the future. We keep asking why, until our curiosity is satiated.
Learning from explanations enables such human-like learning process for machines. We hope explanations, as a way of communication between human and machines, serve to improve learning efficiency, reduce spuriou behaviors, establish trust, and facilitate the development of AI systems beyond solving tasks and pushing accuracy; they think, reason, and learn, as we do.
Reference
Learning from Explanations with Neural Execution Tree. Ziqi Wang*, Yujia Qin*, Wenxuan Zhou, Jun Yan, Qinyuan Ye, Leonardo Neves, Zhiyuan Liu, Xiang Ren. In Proceedings of ICLR 2020. [Paper]
Teaching Machine Comprehension with Compositional Explanations. Qinyuan Ye, Xiao Huang, Elizabeth Boschee, Xiang Ren. In Proceedings of Findings of EMNLP 2020. [Paper] [Project Homepage]
Refining Language Models with Compositional Explanations. Huihan Yao, Ying Chen, Qinyuan Ye, Xisen Jin, Xiang Ren. To appear at NeurIPS 2021 (Spotlight Presentation). [Paper] [Project Homepage]
by Qinyuan Ye, March 13, 2021 (Updated on Oct 20, 2021)